
前言
2023年中的时候突然想本地部署下大模型玩玩,于是某宝700购入了1块TeslaP40,可以上一张双槽显卡,此外P40还需要单独一根8pin转8pin的供电线。
部署环境如下:
- 宿主机:ESXI 6.7
- 虚拟机:Ubuntu22.04 Server
- NVIDIA-SMI:535.154.05
- CUDA Version: 12.2
显卡直通
前置条件
- 需要查询ESXI的版本是否支持P40直通 VMware Compatibility Guide - vsga
- BIOS中需要开启above 4GB
- 虚拟机引导选项为EFI
设备切换直通
ESXI的显卡直通很简单,只需要在硬件里面选中然后点击切换直通就好了,需要重新引导主机下
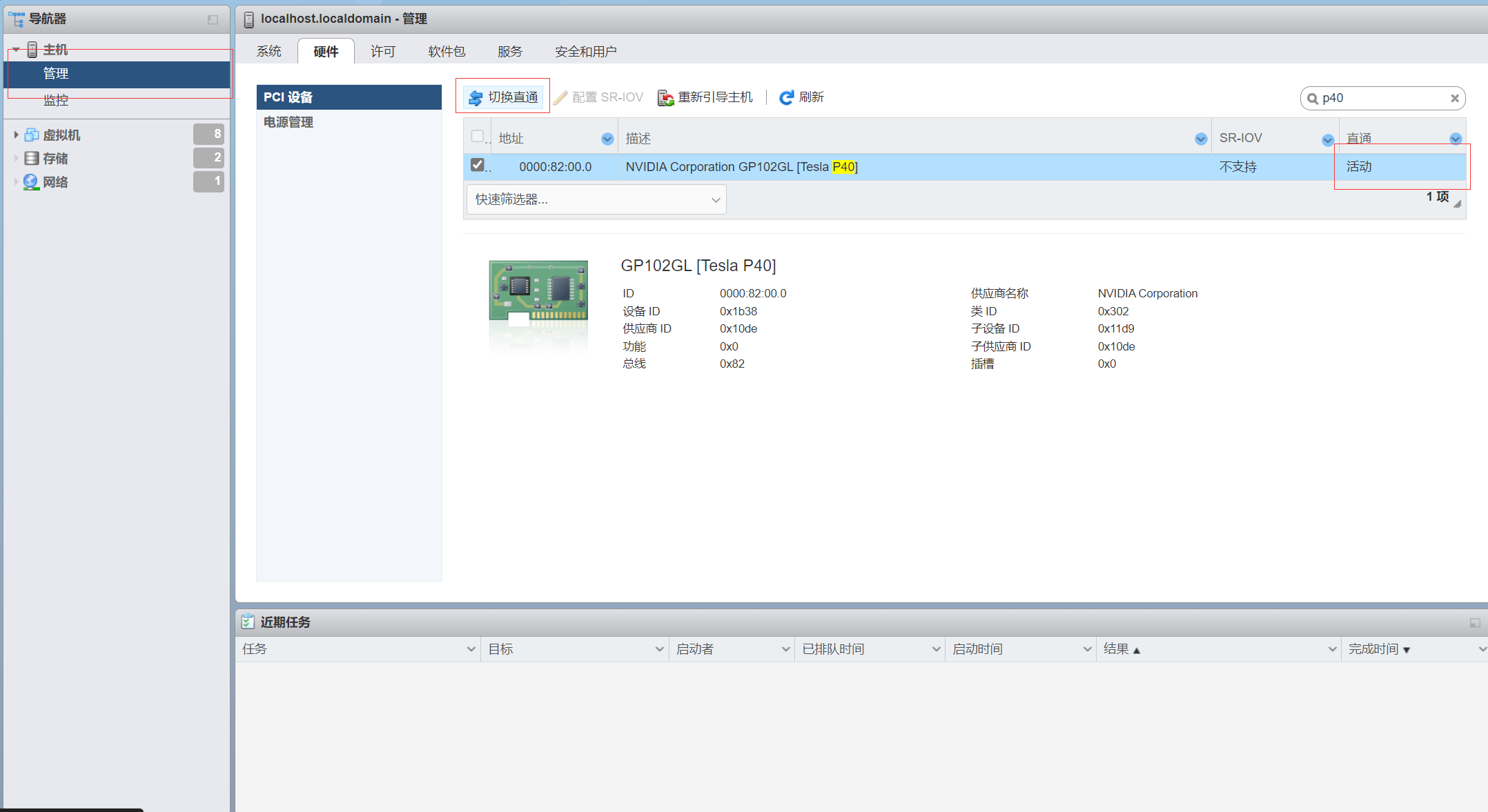
为需要直通的虚拟机分配PCI设备
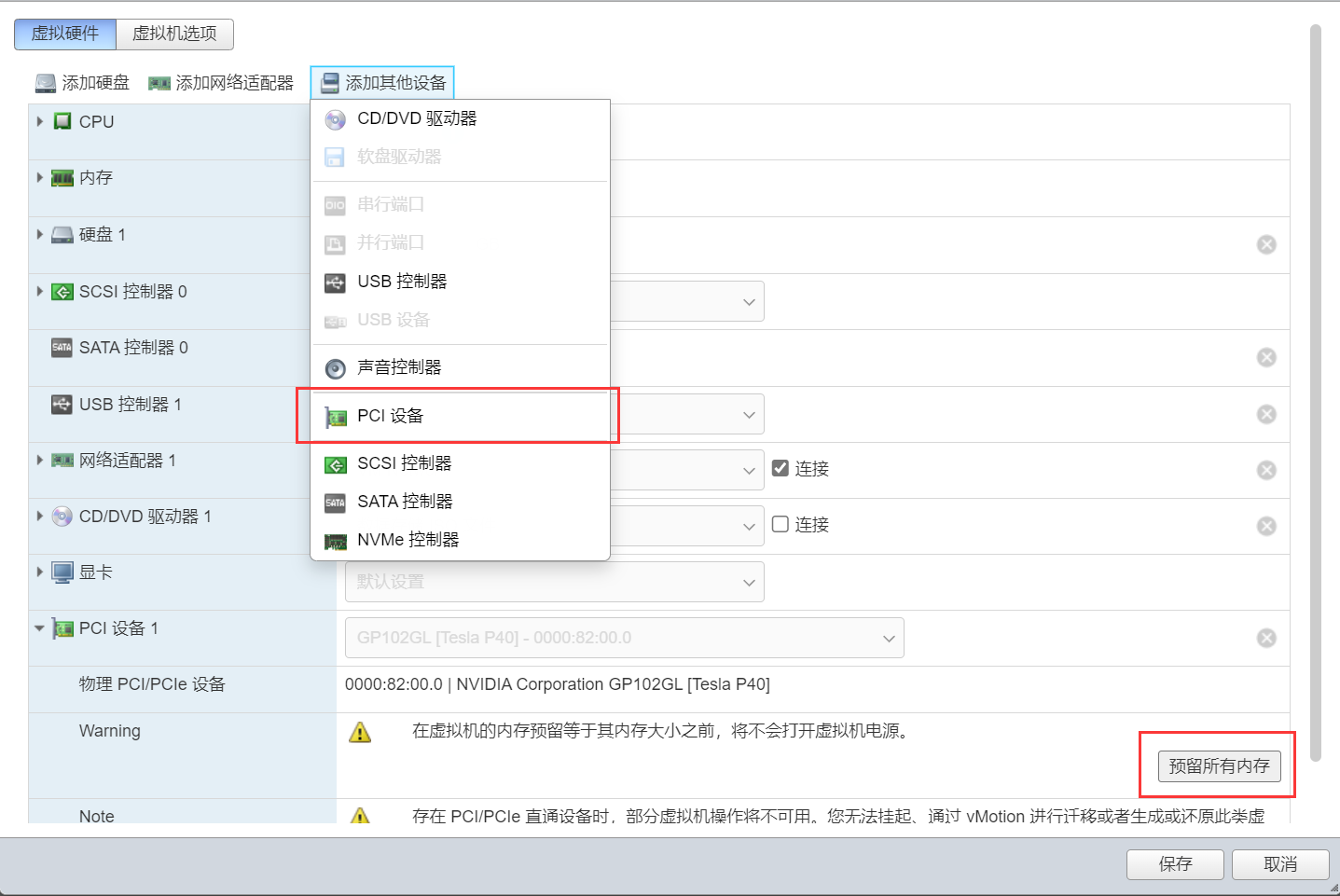
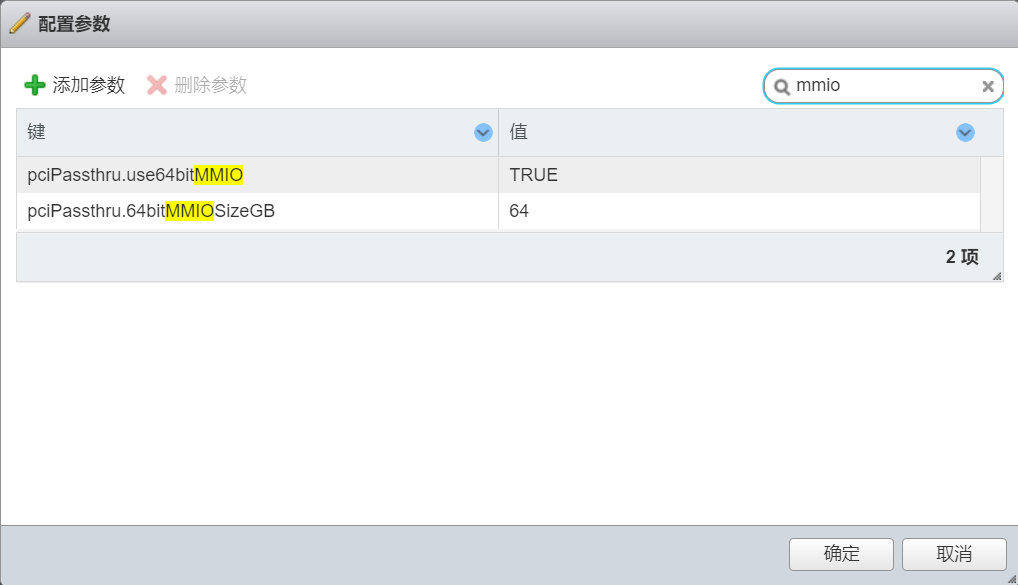
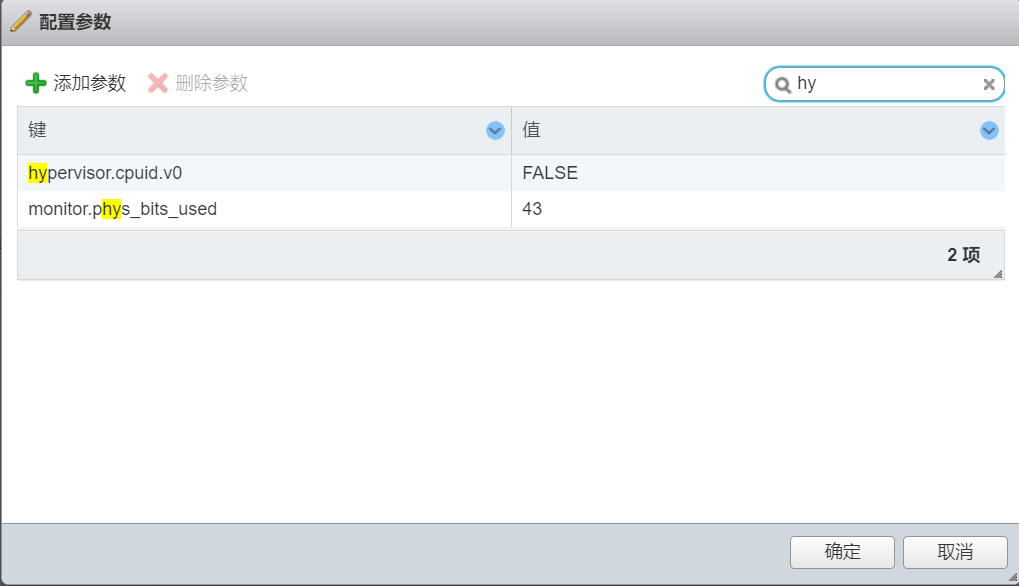
在虚拟机选项->高级->编辑配置 添加参数
| 字段 | 值 |
|---|---|
| pciPassthru.use64bitMMIO | TRUE |
| pciPassthru.64bitMMIOSizeGB | 64 |
| hypervisor.cpuid.v0 | FALSE |
显卡驱动
禁用nouveau驱动
在最后一行添加 blacklist nouveau
|
|
更新驱动
|
|
重启
|
|
查看是否禁用成功
|
|
卸载之前安装的驱动
查看所有与nvidia有关的包
|
|
卸载包
|
|
安装依赖
|
|
安装NVIDIA驱动
从官方驱动 | NVIDIA下载驱动文件
|
|
查看是否安装成功
|
|
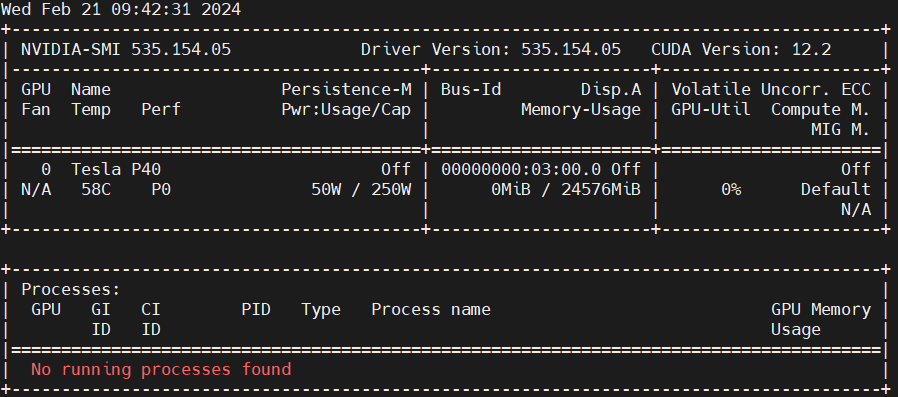
部署模型
ChatGLM3
官方GitHub:THUDM/ChatGLM3: ChatGLM3 series: Open Bilingual Chat LLMs | 开源双语对话语言模型 (github.com)
前置条件
安装git
|
|
|
|
|
|
|
|
pip更换为清华源
|
|
安装anaconda并配置国内源
|
|
|
|
|
|
|
|
|
|
|
|
|
|
拉取源码
|
|
拉取模型
会很大,预留50GB+的空间
|
|
安装依赖
创建虚拟环境
|
|
查看环境
|
|
激活环境
|
|
安装依赖
|
|
注意在创建的conda环境中安装

运行模型
需要注意demo文件中的模型文件路径是否和拉取下来模型文件的路径一致
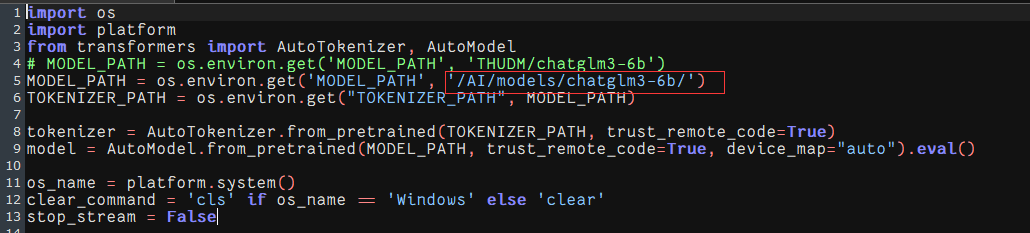
|
|
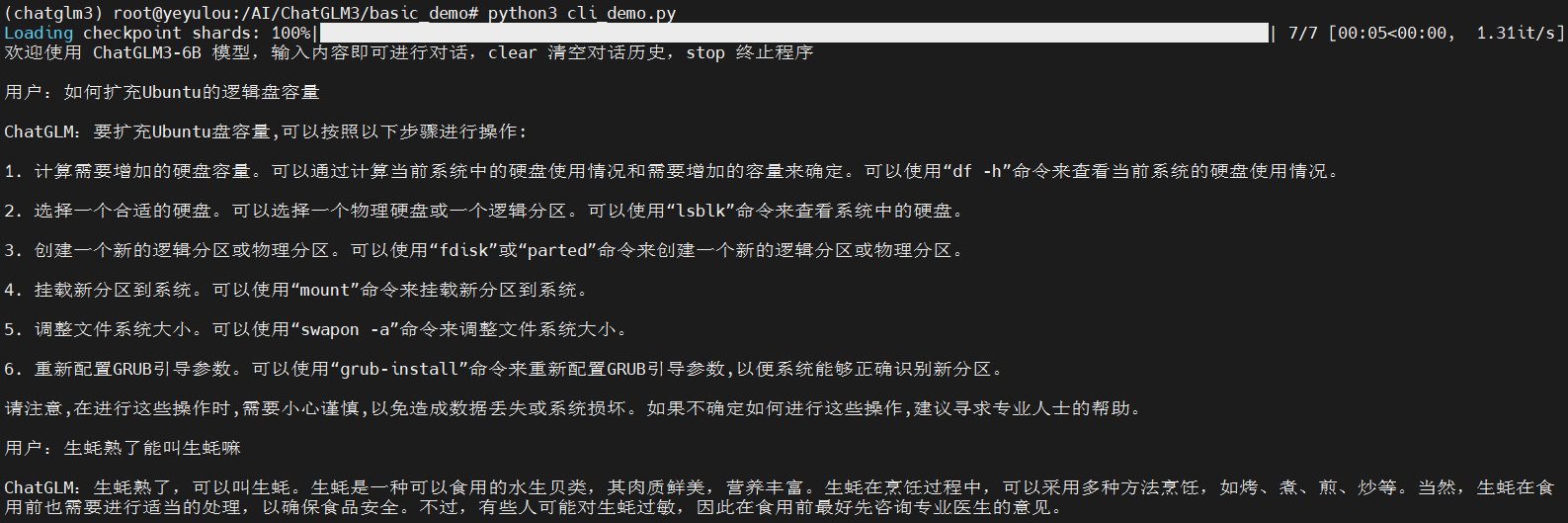
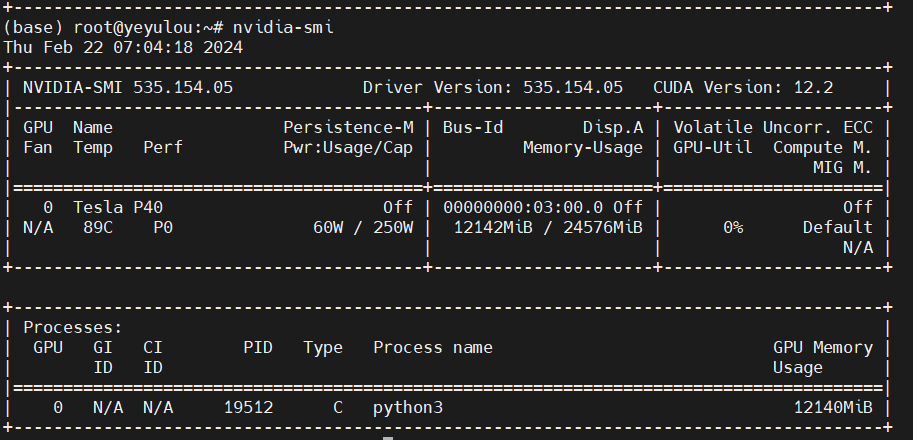 温度爆炸~
温度爆炸~
显卡散热问题
拆除后挡板


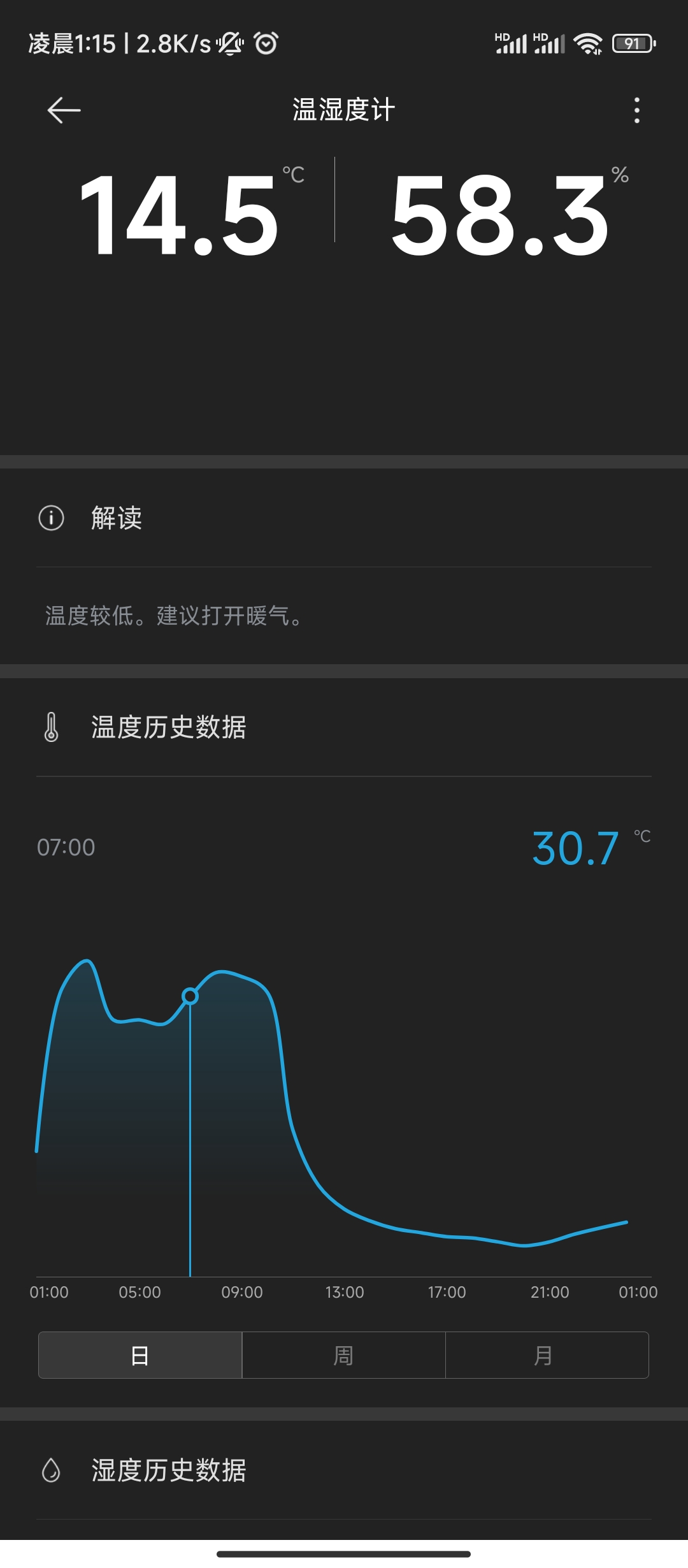
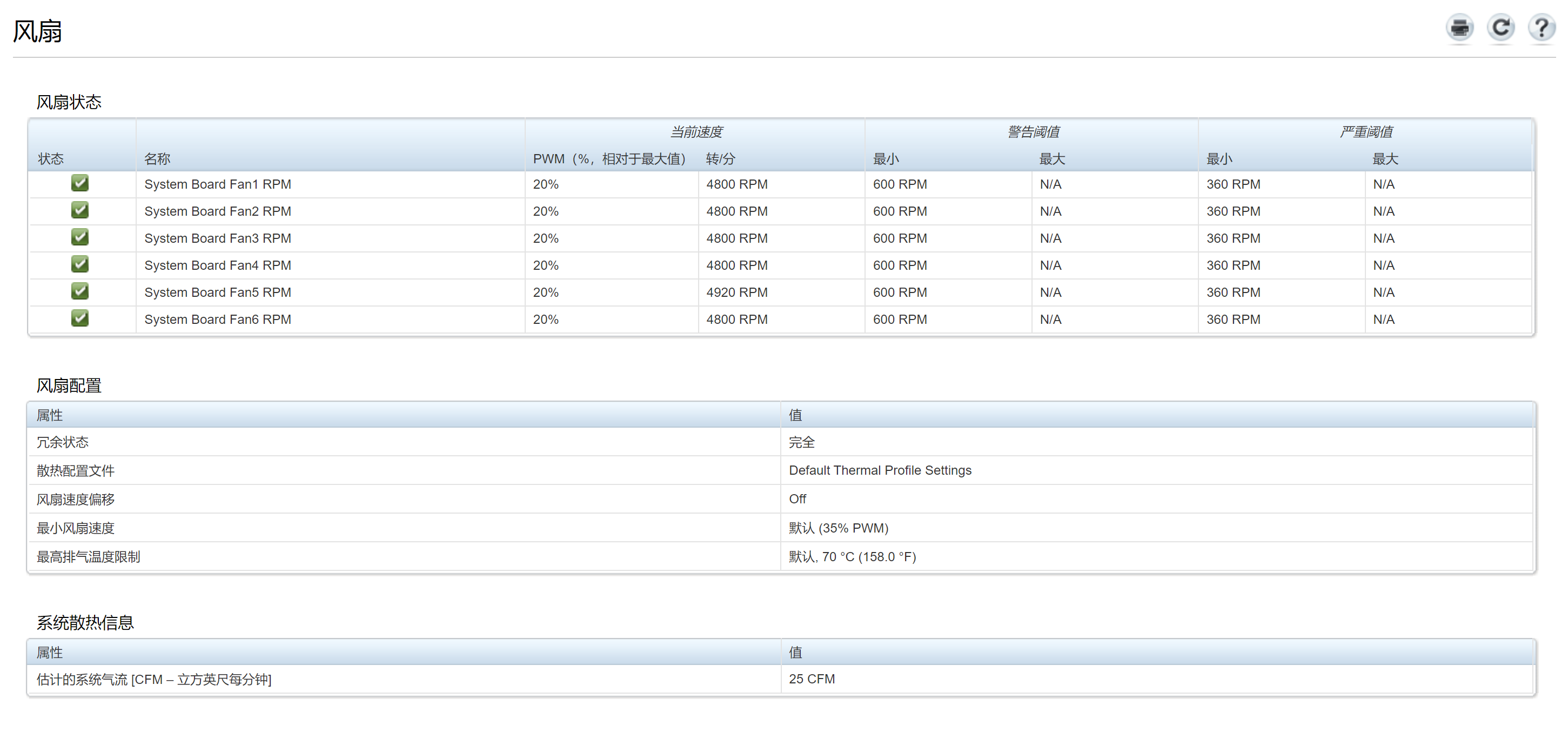
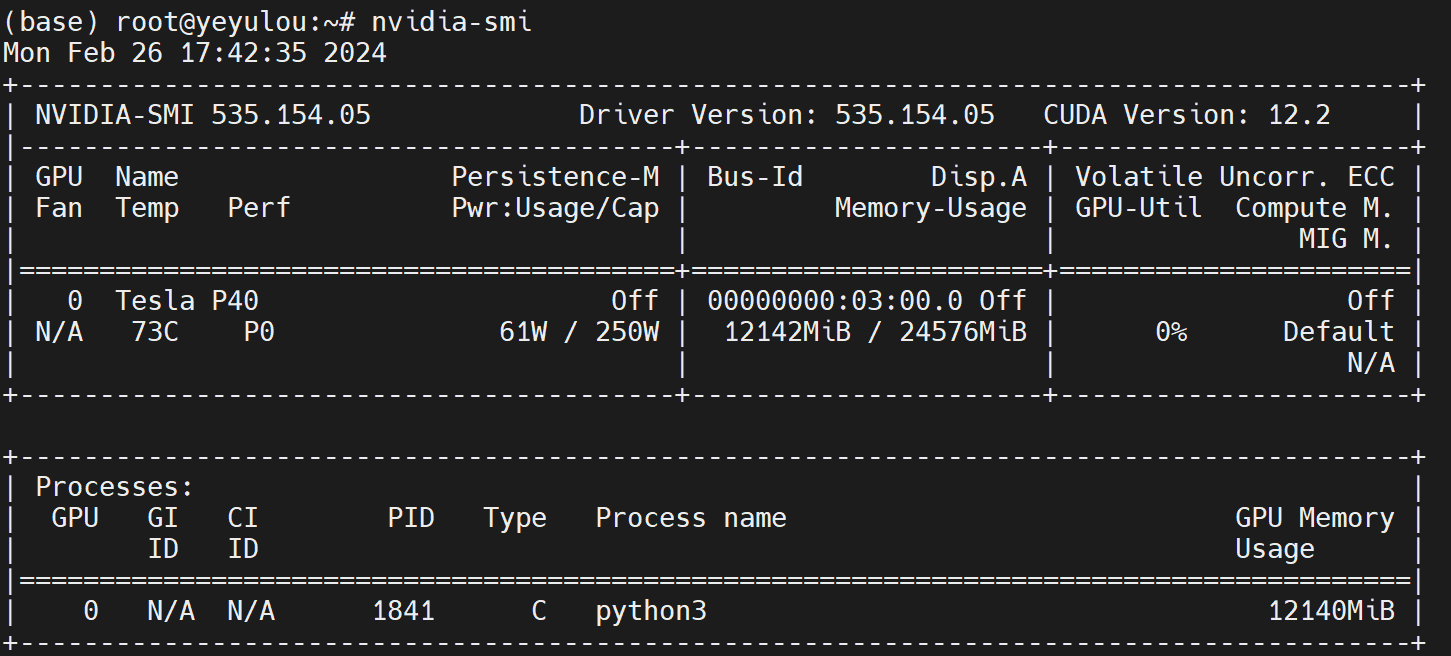
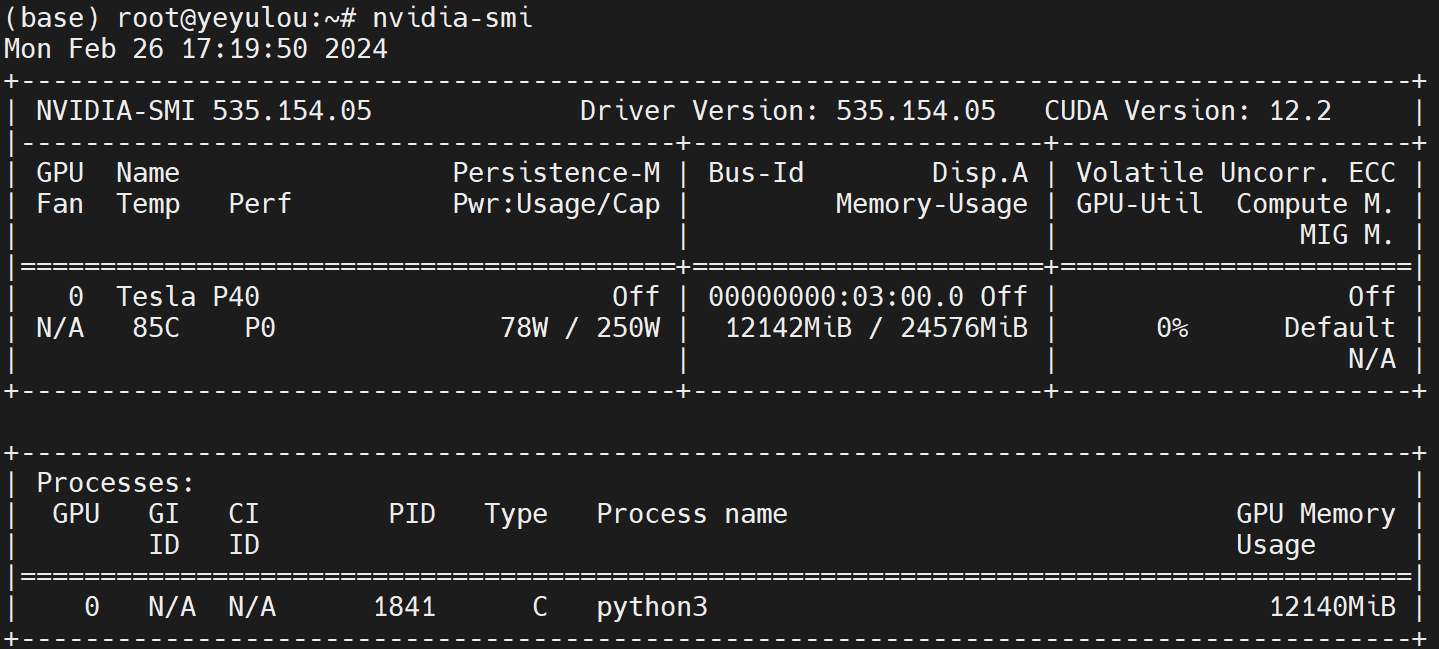
在室温14°和IDRAC风扇转速4800的情况下运行ChatGLM3
- 待机:73°
- 有负载:85°
加装风扇
P40是被动散热所以导致了它的温度只能靠风道或者外挂风扇去解决,但是R730 给P40预留的位置非常小,P40的下方基本上只有1CM,和导流罩之间只有6CM左右。


研究中~
注意事项
- 如果点击切换了直通且重启了,发现直通项还是没有显示“活动”,可能没有开启BIOS的 above 4GB或者ESXI的版本不支持P40直通
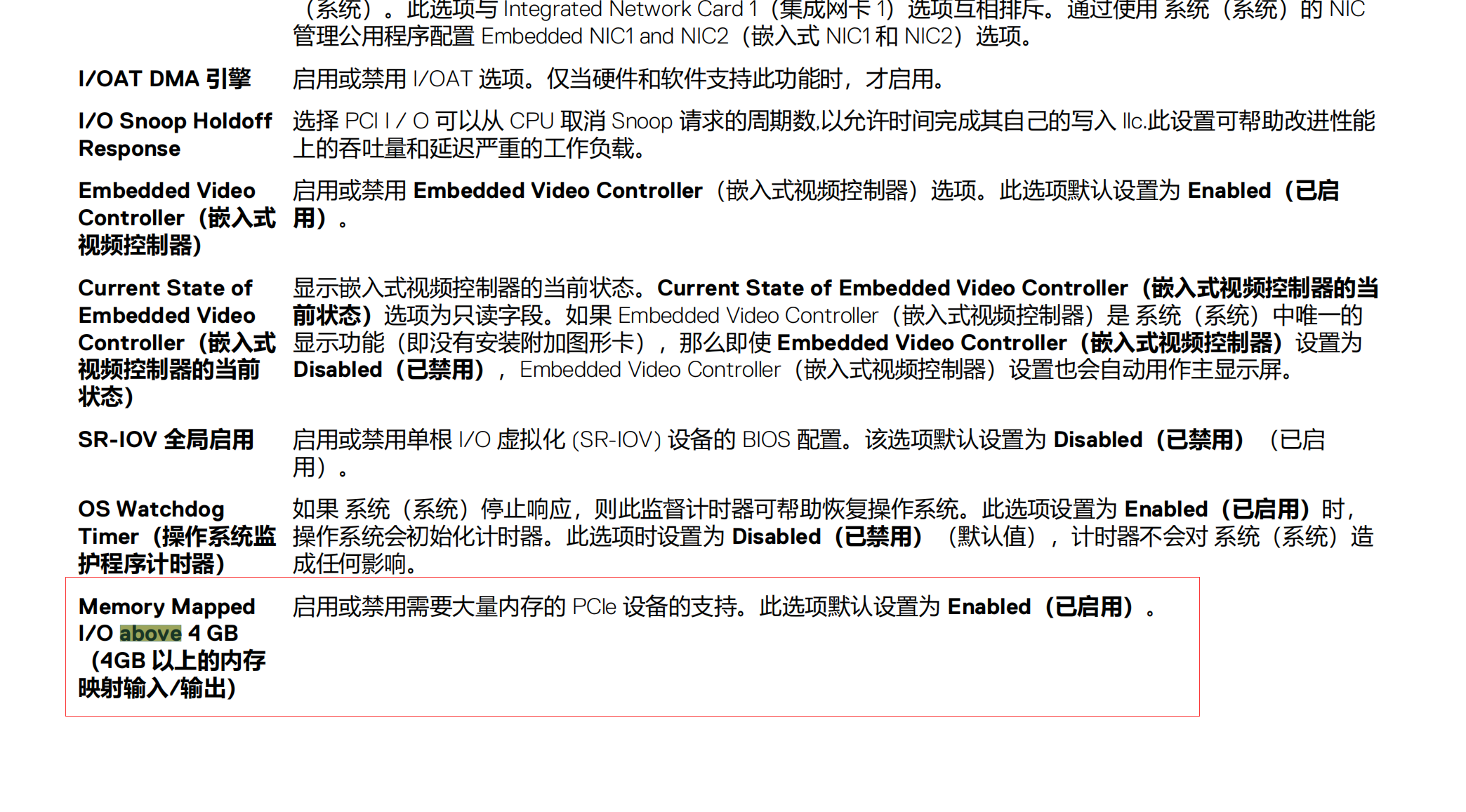
- 虚拟机引导需要是UEFI,否则无法安装驱动或卡住
Windows:安装显卡驱动卡住,且无法连接远程,windows强制关机后无法进入系统一直转logo Linux:成功安装但是nvidia-smi提示No devices were found
- 无法启动虚拟机加载到42%提示失败 需要在虚拟机选项中添加参数
| 字段 | 值 |
|---|---|
| pciPassthru.use64bitMMIO | TRUE |
| pciPassthru.64bitMMIOSizeGB | 64 |
| hypervisor.cpuid.v0 | FALSE |
- 重启Ubuntu nvidia-smi提示"ubuntu NVIDIA-SMI has failed because it couldn’t communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running."
输入以下命令
|
|
也有可能是内核版本自动更新导致的
|
|
参考文章
- ubuntu22.04安装TeslaM40,P40显卡驱动_ubuntu20 tesla p40 安装-CSDN博客
- R730直通Tesla P40显卡 - 知乎 (zhihu.com)
- ESXi 6.5 虚拟机直通K80显卡并安装NVIDIA显卡驱动:_6.5安装显卡驱动-CSDN博客
- 从零开始部署ubuntu+Anaconda3+langchain-chatchat+chatglm3-6b大模型,本地知识库(一)_langchain-chatchat ubuntu 部署-CSDN博客
- 【02】ChatGLM3-6B部署:CentOS7.9本地部署ChatGLM3-6B模型_centos部署chatglm-CSDN博客
- Previous PyTorch Versions | PyTorchPyTorch和CUDA的对应关系
- 冲~!Linux快速部署ChatGLM3-6B,实测效果不错!分享详细操作步骤~~-腾讯云开发者社区-腾讯云 (tencent.com)
- 解决 NVIDIA-SMI has failed - 知乎 (zhihu.com)